
linux指令-grep
grep命令,全称(Global Regular Expression Print,表示全局正则表达式版本),用来做文本匹配十分厉害,堪称神器。
命令格式
1 | grep [option] pattern file |
参数
这里有一个测试文件,内容为:
1 | aaaaaaaaaaaaaaaa |
| 参数 | 作用 | 演示 |
|---|---|---|
| -a | 对二进制数据也匹配 | 无 |
| -A <count> | 除了显示匹配到的内容,还显示他之后的几行内容 |  |
| -b | 显示出之前匹配到了多少 | 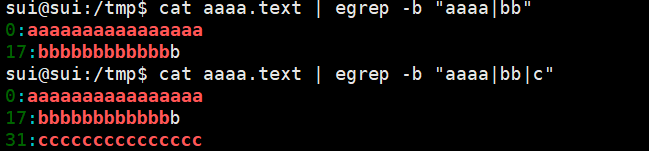 |
| -B <count> | 除了显示匹配到的内容,还显示他之前的几行内容 | 无 |
| -c | 计算符合样式的行数 |  |
| -C <count> | 把-B和-A整合了 |  |
| -f file | 从文件中读取要匹配的文本 | 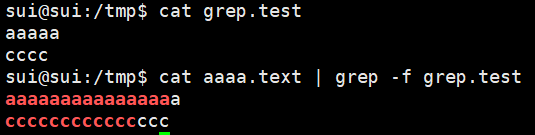 |
| -n | 显示匹配到的文本行号 |  |
| 无 | 从多个文件中查找 |  |
| -i | 忽略大小写 |  |
| -v | 显示不包含匹配项的行 | 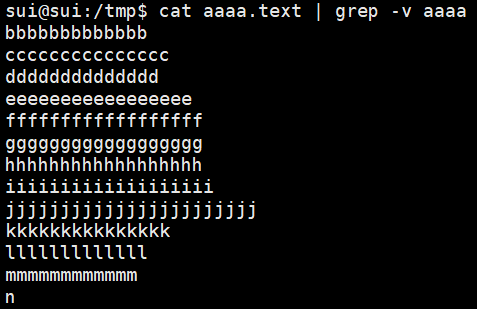 |
| -E | 联合使用 |  |
| -l | 只显示匹配到的文件名,不显示匹配到的内容 | |
| -s | 不显示关于不存在或者无法读取文件的错误信息 | |
| -q | 禁止输出任何匹配结果,而是以退出码的形式表示搜索是否成功,其中0表示找到了匹配的文本行(与echo $? 连用) | |
| -r | 递归查找当前文件夹 |
1 | # 递归查找当前文件夹以及子文件夹下包含pattern的文件 |
表达式规则
| 规则 | 含义 |
|---|---|
| ^ | 指定开头 |
| $ | 指定结尾 |
| . | 任意一个非换行字符 |
| * | 一个或多个前一个出现的字符 |
| [] | 匹配一个指定范围内的字符,如’[Gg]rep’匹配Grep和grep |
| [^] | 匹配一个不在指定范围内的字符,如:’[^A-FH-Z]rep’匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。 |
| \(..\) | 标记匹配字符,如’(love)‘,love被标记为1 |
| \< | 锚定单词的开始,如:’<grep’匹配包含以grep开头的单词的行,类似于^ |
| \> | 锚定单词的结束,如’grep>‘匹配包含以grep结尾的单词的行,类似于$ |
| x\{m\} | 重复字符x,m次,如:’0{5}‘匹配包含5个o的行。 |
| x\{m,\} | 重复字符x,至少m次,如:’o{5,}‘匹配至少有5个o的行。 |
| x\{m,n\} | 重复字符x,至少m次,不多于n次,如:’o{5,10}‘匹配5–10个o的行。 |
| \w | 匹配字母和数字字符,也就是[A-Za-z0-9],如:’G\w*p’匹配以G后跟零个或多个文字或数字字符,然后是p。 |
| \W | \w的反置形式,匹配一个或多个非单词字符,如点号句号等。 |
| \b | 单词锁定符,如: ‘\bgrep\b’只匹配grep。 |
| [[:alnum:]] | 文字数字字符 |
| [[:alpha:]] | 文字字符 |
| [[:digit:]] | 数字字符 |
| [[:graph:]] | 非空字符(非空格、控制字符) |
| [[:lower:]] | 小写字符 |
| [[:cntrl:]] | 控制字符 |
| [[:print:]] | 非空字符(包括空格) |
| [[:punct:]] | 标点符号 |
| [[:space:]] | 所有空白字符(新行,空格,制表符) |
| [[:upper:]] | 大写字符 |
| [[:xdigit:]] | 十六进制数字(0-9,a-f,A-F) |